𝒳-Scene: Large-Scale Driving Scene Generation with High Fidelity and Flexible Controllability
NeurIPS 2025
Abstract

Overview of 𝒳-Scene, a unified world generator that supports multi-granular controllability through high-level text-to-layout generation and low-level BEV layout conditioning. It performs joint occupancy, image, and video generation for 3D scene synthesis and reconstruction with high fidelity.
Diffusion models are advancing autonomous driving by enabling realistic data synthesis, predictive end-to-end planning, and closed-loop simulation, with a primary focus on temporally consistent generation. However, large-scale 3D scenes requiring spatial coherence remains underexplored.
In this paper, we present 𝒳-Scene, a novel framework for large-scale driving scene generation that achieves geometric intricacy, appearance fidelity, and flexible controllability.
Specifically, 𝒳-Scene supports multi-granular control, including low-level layout conditioning driven by user input or text for detailed scene composition, and high-level semantic guidance informed by user intent and LLM-enriched prompts for efficient customization.
To enhance geometric and visual fidelity, we introduce a unified pipeline that sequentially generates 3D semantic occupancy and corresponding multi-view images and videos, ensuring alignment and temporal consistency across modalities.
We further extend local regions into large-scale scenes via consistency-aware scene outpainting, which extrapolates occupancy and images from previously generated areas to maintain spatial and visual coherence.
The resulting scenes are lifted into high-quality 3DGS representations, supporting diverse applications such as simulation and scene exploration.
Extensive experiments demonstrate that 𝒳-Scene substantially advances controllability and fidelity in large-scale scene generation, empowering data generation and simulation for autonomous driving.
Method
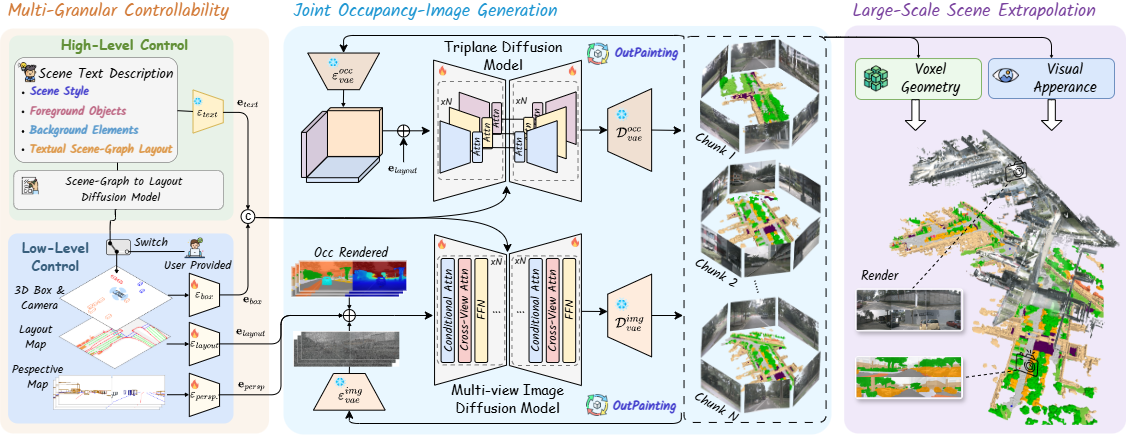
Pipeline of 𝒳-Scene for driving scene generation: (a) Multi-granular controllability supports both high-level text prompts and low-level geometric constraints for flexible specification; (b) Joint occupancy-image-video generation synthesizes aligned 3D voxels and multi-view images and videos via conditional diffusion; (c) Large-scale extrapolation enables coherent scene expansion through consistency-aware outpainting.
𝒳-Scene aims to generate large-scale 3D driving scenes within a unified framework addressing controllability, fidelity, and scalability.
It consists of three main components:
1) Multi-Granular Controllability, which integrates high-level user intent with low-level geometric constraints for flexible scene specification;
2) Joint Occupancy, Image, and Video Generation, which employs conditioned diffusion models to synthesize 3D voxel occupancy, multi-view images, and temporally coherent videos with 3D-aware guidance; and
3) Large-Scale Scene Extrapolation and Reconstruction, which extends scenes via consistency-aware outpainting and lifts them into 3DGS representations for downstream simulation and exploration.
Scene Generation Results
1. Layout-to-Scene Generation
2. Text-to-Scene Generation
3. Large-Scale Scene Generation
BibTeX
@inproceedings{yang2025xcene,
title={X-Scene: Large-Scale Driving Scene Generation with High Fidelity and Flexible Controllability},
author={Yang, Yu and Liang, Alan and Mei, Jianbiao and Ma, Yukai and Liu, Yong and Lee, Gim Hee},
booktitle={The Thirty-ninth Annual Conference on Neural Information Processing Systems},
year={2025}
}